
A Smarter Infrastructure: Automatically filtering an EF 4.1 DbSet
If you drink from the fire hose read Ayende’s blog you would notice a lot of Anti-Repository talk over the past couple years – which I fully agree with.
Back in 2009 he declared repository is the new singleton, stating:
My current approach for data access now is:
- When using a database, use NHibernate’s ISession directly
- Encapsulate complex queries into query objects that construct an ICriteria query that I can get and manipulate further
- When using something other than a database, create a DAO for that, respecting the underlying storage implementation
- Don’t try to protect developers
Naturally he gets a slew of comments asking how he handles certain scenarios without using the repository abstraction. One such question, asked just today is:
With regards to my queries against repositories, Matt asks:
…if my aggregate root query should exclude entities that have, for example, and IsActive = false flag, I also don’t want to repeatedly exclude the IsActive = false entities. Using the repository pattern I can expose my Get method where internally it ALWAYS does this.
Ayende responds by stating that the additional abstraction is not necessary; one can simply rely on making a smarter infrastructure. Since he briefly describes how he would solve it using NHibernate, I figured I would also explain how I solve it using EF 4.1 code-first.
A life without repositories
Like Ayende, I prefer to access my ORM abstraction directly (NHibernate has ISession; I create a single IDataContext). Rather than having separate Repositories for each aggregate root I am able to access all of them directly from the IDataContext.
Using the IDataContext
Here is a typical controller with constructor injection to obtain an IDataContext.
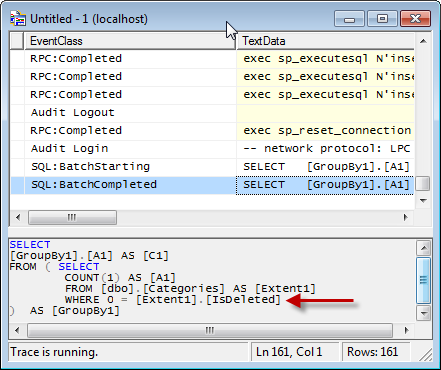
The Categories table has 3 rows in it, but one of them has IsDeleted set to true. If you were to execute the following query, you would see that only 2 of the rows are returned.
public class EFController : Controller
{
private readonly IDataContext _db;
public EFController(IDataContext db)
{
_db = db;
}
public ActionResult Index()
{
// _db.Categories will only return categories where IsDeleted == false
var categories = _db.Categories;
return Content(string.Format("Found {0} active categories", categories.Count()));
}
}
To prove it, here is the SQL Profiler output when I hit the controller from a browser.
Creating the IDataContext
Now let me show you what the IDataContext looks like. It’s pretty simple. Each of the properties are of type IDbSet<T> and not IList<T>, which would commonly be found in a repository abstraction.
public interface IDataContext
{
IDbSet<Category> Categories { get; set; }
IDbSet<Product> Products { get; set; }
}
“OMG you’re spreading EF throughout your entire app!”
IDbSet comes from EntityFramework.dll. This means that anyone who uses the IDataContext will have some (small) knowledge of Entity Framework. Some developers are very concerned over this architectural dependency.
My argument is that Entity Framework, like any popular ORM, is already an abstraction over your database. It will take care of translating your needs into the appropriate SQL depending on the underlying store (MSSQL, Oracle, etc). As a firm believer in YAGNI, I highly doubt I will need to swap out my entire data access layer some day down the road, so why should I introduce architectural complexity for something that will very likely never come up? And even if it somehow does, I don’t know of a single instance where an application has been able to seamlessly swap completely different data stores (like going from SQL Server to RavebDB), without redesign, significant code re-write, and re-testing.
Implementing the IDataContext (and adding filtering into our infrastructure)
Below is our concrete data context. It inherits from DbContext (From EF) and implements the interface we created. EF will automatically initialize the DbSet properties for us (as in the case of Products below), but we could also initialize it ourselves (as in the case of Categories).
Using this answer from StackOverflow I found a great implementation of IDbSet called FilteredDbSet, which takes an Expression in the constructor to represent a WHERE clause. This WHERE clause will be automatically added to every query against the Categories property (and of course, translated all the way to SQL).
Since consumers of the IDataContext are only ever working with IDbSet, they have no idea that this automatic filtering is taking place behind the scenes. Hooray: a smarter infrastructure.
public class ECommerceDb : DbContext, IDataContext
{
public ECommerceDb()
{
// Automatically filter out Categories where IsDeleted == false
Categories = new FilteredDbSet<Category>(this, c => c.IsDeleted == false);
}
public IDbSet<Category> Categories { get; set; }
public IDbSet<Product> Products { get; set; }
}
What about Unit Testing?
Repositories offer a great unit testing abstraction. And so does this design. IDataContext exposes properties of type IDbSet – which is an interface just like IList, and ripe for the mocking!
Someone has even created a great InMemoryDbSet and added it to NuGet for our consuming pleasure.
https://nuget.org/packages/FakeDbSet
Now it becomes painlessly simple to create a fake IDataContext instance and populate it with InMemoryDbSets just like an in-memory repository would offer.
What about accessing the unfiltered set?
Kevin LaBranche asked below how I might handle a scenario where I needed to bypass the filter, such as for reporting. One way to solve this would be to create an Unfiltered extension method which could check if the IDbSet is a FilteredDbSet, and if so, return underlying set instead of the filtered one.
public static class DbSetHelper
{
public static IQueryable<TEntity> Unfiltered<TEntity>(this IDbSet<TEntity> set) where TEntity : class
{
var filteredDbSet = set as FilteredDbSet<TEntity>;
return filteredDbSet != null ? filteredDbSet.Unfiltered() : set;
}
}
Note: I also had to add the following method to the FilteredDbSet class
public IQueryable<TEntity> Unfiltered()
{
return _set;
}
Which could then be used as follows:
public ActionResult Index()
{
var categories = _db.Categories;
var unfiltered = _db.Categories.Unfiltered();
return Content(string.Format("Found {0} active categories. Found {1} total.", categories.Count(), unfiltered.Count()));
}
Summary
Like the saying goes: complexity is easy; simplicity is hard.
Striving for a clean and simple architecture, without needless layers of complexity, is a goal we should all have. Sometimes it makes sense to try and make your infrastructure smarter, instead of adding yet another layer of indirection.



Leave a Comment